
1. 事件起因
国家开放大学运维人员反应 MaxBI仪表板 的分析图表卡片加载缓慢,部分卡片的加载时间长达数十分钟,仪表板功能基本处于不可用,用户无法忍受。
2. 原因排查
2.1 直接原因
通过堡垒机登录到服务器上,登录进 Mysql ,通过 show processList 查看当前所有的查询,发现存在大量的慢查询已经过去十几分钟, top 命令排查数据库所在的服务器 CPU 被 Mysql 进程打满;分析了大量卡死的 Sql,发现这些复杂的 Sql 执行速度的确很慢,原因是用户创建了很多复杂的分析卡片,这些分析卡片被解析成十分复杂的 Sql。
2.2 业务原因
因为仪表板一次展示15个卡片,相当于每当有一个用户打开页面,后台就要请求15次数据库,且同部门的人共享一个仪表板。仪表板接口的QPS在300左右,等于每秒需要查询数据库300次。如果 Sql 不复杂 | 表的数据量不大,300/s 的连接对数据库是基本没有压力的,但是用户数仓库表的大小我们的系统是没有办法控制的,并且随着卡片分析功能的不断迭代,最终卡片解析出来的 Sql 也越来越复杂,所以导致很多复杂的查询(因为索引字段无法做到全覆盖)进行全表扫描,最终拖垮数据库,打满服务器 CPU。
3. 优化实现
一、仪表板是一个典型的 热点读场景,通过缓存可以起到很好的优化效果
二、针对第一次请求,某些复杂的 Sql 还是很慢,怎样解决呢?通过 TPC-DS标准 Sql 测试,Trino 在大表下的复杂查询的性能比 Mysql 高出一个量级(性能提升跟 Trino 集群的配置相关),且 Trino 作为 MPP 框架配合 Kurbernetes Autoscaler 可以做到很好的动态扩缩容。使用 Trino 替代 JDBC 作为某些复杂 Sql 的查询引擎可以很好的解决这个问题。
3.1 Redis缓存设计
常用的缓存更新模式有:Cache Aside (旁路缓存模式)、Read/Write Through Pattern(读写穿透模式)、Write Behind Pattern(异步缓存写入)
这里采用的是 Cache Aside (旁路缓存模式)
一、将 微服务名:表名:字段名:card_id 作为缓存的 key。需要注意的是,保证语义的前提下,key 的长度也需要控制。例如
maxbi:analysis_card:{card_id} 简化为 m:ac:id:{card_id}
二、缓存查询逻辑:每次请求先查询缓存,如果缓存不存在,则查询数据库,然后将结果写入缓存。
三、缓存更新逻辑:卡片逻辑被更新,则删除对应的缓存。
上述方案在项目中的具体实现如下图:更新 DB 之后,进行缓存删除操作,如果删除缓存失败,则将删除缓存操作封装成消息,发送至消息队列,通过消费者进行消费,再次进行删除操作。
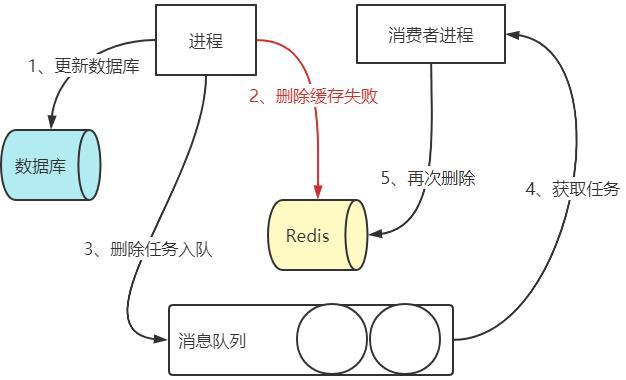
更新DB之后删除缓存,理想情况删除缓存成功,可是总会存在各种各样的原因(例如服务器宕机、网络故障、redis 故障等等)导致发送删除缓存消息那一步失败,所以我们得进行额外的补偿机制。 DB 更新与消息发送的原子性怎么保证呢?我们通过 RocketMQ 半事务消息解决,大体实现通过消息反查机制,判断本地事务是否成功,成功的话当前消息才可见。
3.2 数据一致性风险与保障:
在高并发情况下,如果不加以控制,则会存在数据不一致的问题。
-
缓存读取和与 DB 更新并发

这种情况下,某些请求可能读取到的是旧数据。如果用户觉得数据不对,其实刷新重试就可以拿到更新之后的数据(某些银行APP的个人资产那里的金额也是这种处理逻辑)。 -
缓存更新与 DB 更新并发

如上图,最终缓存中写入的数据还是旧数据,这种情况下就会出现数据不一致。实际上因为 查数据库 -> 写缓存 比 更新数据库 -> 删除缓存 要快很多,出现这种情况的概率是非常小的。就是因为出现的概率小我们就要这样放任不管吗?NO~~~😝😝😝有办法可以减少这种不一致带来的影响或者完全避免呢?有滴😁😁😁
- 如果业务实时性要求不高,则可以给缓存设置一个较短的过期时间。
- 如果对实时性要求较高,则需要给关键步骤加上分布式锁了。实施的方案如下

-
缓存读取与 DB 更新的并发控制
查询操作流程中,先判断 lock 是否存在,若存在,则表示当前 DB 或缓存正在执行更新操作,不能走缓存,转而直接走 DB 返回数据。缓存仅作为 “DB 降压” 的辅助手段,在不确定缓存数据是否最新的情况下,宁可多查询几次 DB,也不要查询到缓存中的不一致数据。此外,更新操作相对于查询操作是很少的,卡片分析接口中,读写比例约为 20:1。
另一种可行的方案是可在检测到有锁后可进行短暂的等待和重试,好处是可进一步增加缓存的命中率,但是多一次锁等待,可能会影响到查询接口的性能。
同时,也要考虑缓存服务异常的情况,在锁检测、缓存查询异常发生的时候需要进行降级处理,并在调用缓存服务前增加了降级开关判断,若降级开关开启,也会直接查询 DB。 -
缓存更新和 DB 更新的并发控制
查询操作流程中,若缓存不存在,则进行缓存的更新。在更新时候先尝试进行加锁,若当前有锁说明当前已有线程在进行 DB 或缓存的更新,则进行等待和重试,从而可避免查询到 DB 中的老数据更新到缓存中。
接下来从实现的角度分别描述一下基于本地消息表的缓存删除策略,缓存的降级和恢复这两个方面的具体方案。 -
缓存删除策略
在更新操作中,先更新 DB,再删除缓存。缓存删除失败的补偿如上面所说通过消息队列发送半事务消息弥补。
4. 总体优化措施
- 将仪表板卡片缓存过期时间在基础时间上 + 随机时间,防止同一时刻缓存集体失效带来的
缓存雪崩。 - 为了严格进行参数校验,对于不合理的 card_id 直接拦截,避免
缓存穿透(测试老师总是能够以出其不意的角度发送一些刁钻的请求😫😫😫) - 整个查询接口有
熔断、降级处理,一旦查询服务不可用,请求失败次数达到阈值,打开熔断开关,不调用查询服务,直接返回兜底数据。
查询服务这边如果发现 Redis 缓存出现异常,则将查询降级到 DB。(血泪教训啊,一定要做兜底操作。实施人员调整了华为云网络组,然后应用不能正常访问 Redis,请求在经历失败重试之后,全部打到了数据库上,数据库又没有做限流控制,直接将数据库打满🙃🙃🙃) - 卡片 DB 查询通过
Sentinel进行了限流控制。 - 增加引擎智能调度功能:模型被创建的时候,后台会统计模型所关联的表的记录数,超过一定的数据量,则会将 Trino 作为查询引擎。一张表如果数据量越大,则 Trino 的查询优势就越明显。某些场景下查询速度从 5分钟 降低到 4秒钟,进步不可谓不明显。当然,Trino 也是经历过很多次的参数调优、JVM 优化,并且在容器化部署 Trino 时也暴露出了很多的问题。目前唯一没有解决的问题就是 coordinate 的单点故障。
5. 总结
这次项目对缓存的使用更进一步,让我对整个缓存设计与相关注意点有一个大体的了解,缓存真是性能提升的利器!整个方案其实还有一些没有解决的问题,比如 Redis 服务出现异常之后被熔断,当熔断时间结束之后,Redis 中肯定存在旧数据,直接读缓存会有问题。现阶段使用的公有云的缓存服务,可用性还是很不错的,截至目前还没有出现过故障。